
Label protocol
Recognizing and accurately labeling the complex cloud patterns requires specialized knowledge. To achieve the highest label accuracy for CloudSEN12+, we have meticulously designed a comprehensive five-step protocol that effectively addresses the unique challenges that cloud labeling poses.
This protocol is not only applicable to CloudSEN12+ but can also be adapted to enhance labeling accuracy in various remote sensing tasks. Our protocol is built around IRIS, a semi-automatic tool designed for manual segmentation of multi-spectral and geospatial imagery. This tool aids in achieving precise and consistent labeling by leveraging machine learning assistance while allowing for human oversight and adjustment.
1. Sampling: Manual sampling remains the most effective approach, despite being time-consuming. The vast array of cloud types and their unique characteristics demand careful consideration. To address this, labelers prioritize atypical clouds, such as contrails, ice clouds, and haze/fog, over more common varieties like cumulus and stratus. Furthermore, using a reference model to determine which data points should be included in a dataset is helpful. Labelers make informed decisions about which samples to prioritize by comparing human interpretation with the reference model.
2. Agreement: Before starting the labeling process, all labelers come to a mutual agreement on the definitions and criteria for each semantic class, creating common guidelines. When ambiguity arises, and a pixel could belong to multiple classes, the priority attribute is established to determine the final allocation based on the higher priority class. This prioritization strategy ensures consistent labeling decisions, particularly in borderline cases. Additionally, all labelers agree on a specific metric to optimize. For CloudSEN12+, the chosen metric is the F2-score, which places more emphasis on recall in the evaluation. This prioritization highlights errors in thick clouds and cloud shadows over those in thin clouds and clear classes. Lastly, specific band combinations are established to aid cloud detection.
3. Training: Labelers follow a comprehensive training program designed to teach them to agree with the labeling software and enhance their skills in ambiguous scenarios. The program begins with an in- depth review of accurately labeled image examples, enabling participants to align with the established standards and expectations for labeling. Furthermore, the training encompasses hands-on practical sessions, during which labelers put their learning in real-time scenarios and receive constructive feed- back to sharpen their labeling skills. The training stage is pivotal in ensuring that all contributors are thoroughly prepared and maintain consistency in their labeling efforts.
4. Production: The labeling process is conducted in this stage. Labelers can start labeling from a blank canvas or fine-tune the preliminary cloud mask predictions provided by the CloudSEN12 UnetMobV2 model. Each labeler undertakes the task independently.
5. Quality Control: The labels go through a double-blind quality control process that involves all the labelers to ensure their integrity and accuracy. If more than two independent reviewers report a label, it is sent back to the production stage. Additionally, all human-generated labels exhibiting a Perror equal to 1 (see Semi229 automatic label quality section) are subject to a meticulous re-examination.
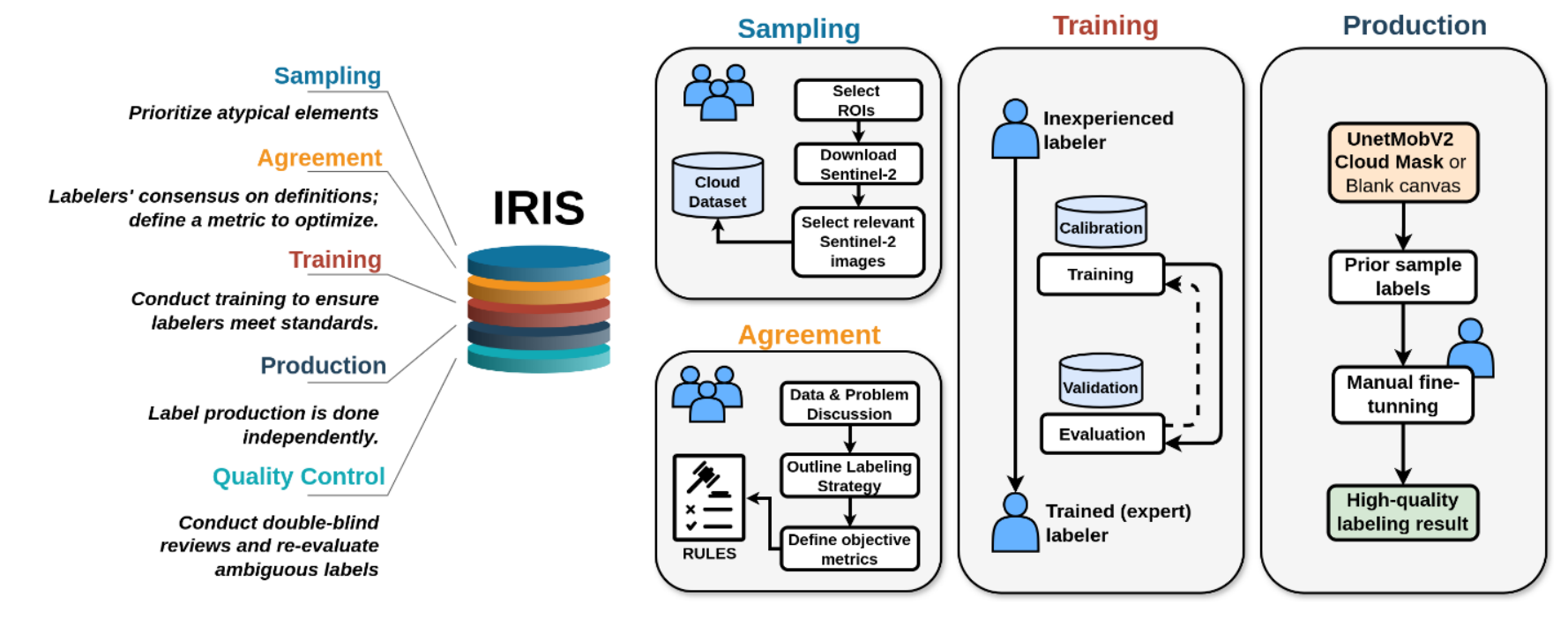
The image illustrates our cloud detection protocol, structured into five stages: Sampling, Agreement, Training, Production, and Quality Control. The IRIS graphical user interface is integral to each of these stages.