
Manual labeling improvements
In CloudSEN12+ we have improved the manual labeling of the images. CloudSEN12+ employs a dual-scoring approach to detect potential human errors in semantic segmentation.
Initially, we calculate the trustworthiness index (TI), which compares the cloud mask prediction from a reference model with the corresponding human annotations used as ground truth. We have selected the CloudSEN12 UnetMobV2 as the best available reference model. The TI is computed using the F2 multi-class score, adopting a one-vs-all macro strategy.
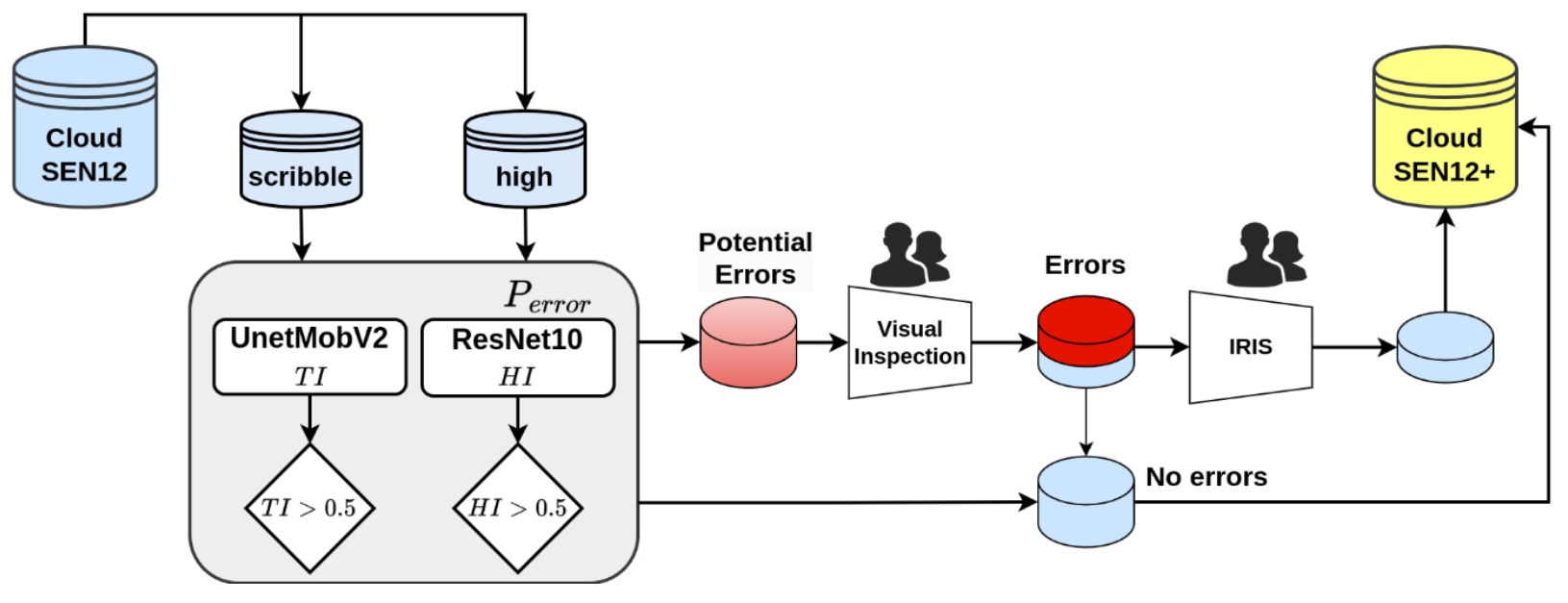
A high-level summary of our workflow to detect human errors. Prediction accuracy (TI) and sample difficulty (HI) are used to identify errors in high-quality and scribble subsets.
Annotation errors are more susceptible in challenging scenarios, such as class boundaries, intricate cloud shapes, or insufficient contextual information. To address this, we incorporate a Hardness Index (HI) that considers the perceived difficulty of the labelers during the annotation process. In order to build this index, a ResNet-10 model is trained with the S2 images as input and the labelers’ perceived difficulty as the target, which is included in the metadata of the CloudSEN12 dataset. This model effectively accounts for the complexity of the annotation task and helps identify areas where errors are more likely to occur.
Around 5% of the images are selected for re-annotation based on the TI and HI scores. The figures below illustrate examples of human labeling before and after the review process.

Label correction in the high quality subset. The images come from the ROIs: 10133, 720, and 1953.

Correcting labels in the scribble subset. These images originate from ROIs 1909, 3472, and 3474. The varying shades of yellow, green, and red represent the edges (darker) and center (lighter) of the annotations.